
https://programmers.co.kr/learn/courses/30/lessons/81303
코딩테스트 연습 - 표 편집
8 2 ["D 2","C","U 3","C","D 4","C","U 2","Z","Z"] "OOOOXOOO" 8 2 ["D 2","C","U 3","C","D 4","C","U 2","Z","Z","U 1","C"] "OOXOXOOO"
programmers.co.kr
풀이
이 문제는 효율성 테스트까지 통과해야합니다. 따라서 각 행들의 관계를 '링크드리스트(Linked List)' 자료형으로 정의하여 풀어야합니다. 일반 배열 자료형에 비해 링크드리스트의 경우 삭제/삽입의 시간복잡도가 O(1)인 점을 이용하여야 합니다.
링크드리스트에 대한 개념이 없는 분은 다음 링크를 참조하세요.
https://namu.wiki/w/%EC%97%B0%EA%B2%B0%20%EB%A6%AC%EC%8A%A4%ED%8A%B8
1. 링크드리스트 초기화
링크드리스트 노드 선언
|
1
2
3
4
5
|
class Node:
def __init__(self):
self.prev = -1 # 이전 노드 인덱스
self.next = -1 # 다음 노드 인덱스
self.is_delete = False # 삭제 여부
|
cs |
링크드리스트 구성을 위한 노드를 다음과 같이 선언합니다. 이중 링크드리스트(양방향 링크드리스트)로 구성하기 위하여 prev에는 이전 노드의 index를, next에는 다음 노드의 index를 저장합니다.
추후 default 값은 -1인 점을 첫 번째 노드와 마지막 노드의 예외처리에 이용합니다.
is_delete 변수로 해당 노드가 삭제되었는지 아닌지를 판단합니다.
링크드리스트 초기화
|
1
2
3
4
5
6
7
8
9
|
def solution(n, k, cmd):
# 1. 링크드리스트 초기화
node_list = [Node() for _ in range(n)] # 노드 리스트 생성
for i in range(n - 1):
node_list[i].next = i + 1 # i 번째 노드의 next는 i+1
node_list[i + 1].prev = i # i+1 번째 노드의 prev는 i
...
|
cs |
위에서 선언한 Node를 원소로 가지는 리스트를 생성합니다.
5~7번 라인에서 i 번째 노드와 i+1 번째 노드를 연결합니다. ( i 번째 노드의 next는 i+1, i+1 번째 노드의 prev는 i)
5번 라인에서 range(n-1)임을 주의하세요. 그림으로 나타내면 다음과 같습니다.

2. 삭제된 노드 처리용 스택
|
1
2
3
4
5
6
|
def solution(n, k, cmd):
...
# 2. 삭제된 노드를 저장할 스택
del_stack = deque()
|
cs |
삭제된 노드를 다시 복구하는 경우 최근에 삭제된 노드부터 복구하기 때문에 스택(stack) 자료형을 이용합니다. (LIFO, Last Input First Out) 여기서는 collections의 deque를 이용하여 스택을 구현하였습니다.
3. 명령어 처리
명령어는 총 4가지로 구성되어 있습니다. (U, D, C, Z). 이 때 U, D의 경우 얼마나 이동할 건지에 대한 수가 문자열 뒷부분에 명시되어 있기 때문에 다음과 같이 문자열을 분리합니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
|
def solution(n, k, cmd):
...
cur = k # 현재 가리키고 있는 노드의 인덱스
# 3. 명령어 처리
for c in cmd:
if len(c) > 1:
c, move_size = c.split(' ')
move_size = int(move_size)
...
|
cs |
7번의 for문은 cmd 리스트에서 문자열을 c라는 변수로 하나씩 가져옵니다.
이 때 c가 "C" 혹은 "Z" 명령어인 경우 len(c)는 1입니다. c가 "U" 혹은 "D" 명령어의 경우 len(c)는 1보다 큰 값을 가집니다. (ex. U 10)
따라서 c가 "U" 혹은 "D" 명령어인 경우 9번 라인에서 split() 함수를 이용하여 c를 명령어와 숫자로 분리합니다. move_size에는 숫자가 문자열 형태로 저장되므로 10번라인에서 int형으로 변환하여 줍니다.
명령어가 "U" 혹은 "D" 인 경우
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
def solution(n, k, cmd):
...
cur = k # 현재 가리키고 있는 노드의 인덱스
# 3. 명령어 처리
for c in cmd:
...
if c == "U":
for i in range(move_size):
cur = node_list[cur].prev # cur을 cur 노드의 prev로 교체
elif c == "D":
for i in range(move_size):
cur = node_list[cur].next # cur을 cur 노드의 next로 교체
|
cs |
명령어가 U 혹은 D인 경우 현재 가리키고 있는 노드의 인덱스를 바꿉니다.
U 명령어인 경우 현재 가리키고 있는 노드(cur)의 prev를 cur에 할당합니다.
반대로 D 명령어의 경우 현재 가리키고 있는 노드(cur)의 next를 cur에 할당합니다. 이 동작을 move_count 만큼 반복합니다.
그림으로 나타내면 다음과 같습니다.

만약 위의 예시에서 Node 1이 삭제된 경우라면 다음과 같습니다.

c=D인 경우도 동작은 같습니다. 다만 cur이 prev가 아닌 next로 움직이게 됩니다.
명령어가 "C"인 경우
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
def solution(n, k, cmd):
...
cur = k # 현재 가리키고 있는 노드의 인덱스
# 3. 명령어 처리
for c in cmd:
...
elif c == "C":
node_list[cur].is_delete = True # 현재 노드에 삭제 표시
del_stack.append(cur) # 스택에 삭제된 노드 번호 추가
prev_node = node_list[cur].prev # 이전 노드 번호
next_node = node_list[cur].next # 다음 노드 번호
if prev_node != -1: # 이전 노드가 있는 경우
node_list[prev_node].next = next_node # 이전 노드의 next를 삭제된 노드가 가리키던 next로 교체
if next_node != -1: # 다음 노드가 있는 경우
node_list[next_node].prev = prev_node # 다음 노드의 prev를 삭제된 노드가 가리키던 prev로 교체
cur = next_node # 가리키고 있는 노드를 next_node로 갱신
else: # 만약 다음 노드가 없는 경우
cur = prev_node # 가리키고 있는 노드를 prev_node로 갱신
|
cs |
명령어가 C인 경우 현재 가리키고 있는 노드를 삭제합니다.
현재 노드에 삭제를 표시하고 스택에 삭제된 노드의 번호를 추가합니다. 그리고 현재노드의 prev 노드와 next 노드를 서로 연결합니다. 그림으로 나타내면 다음과 같습니다.

그리고 현재 가리키고 있는 노드를 next로 갱신합니다. 만약 next 노드가 없는 경우 prev 노드를 가리킵니다.
명령어가 "D"인 경우
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
def solution(n, k, cmd):
...
cur = k # 현재 가리키고 있는 노드의 인덱스
# 3. 명령어 처리
for c in cmd:
...
elif c == "Z":
del_node = del_stack.pop() # stack의 가장 상위 요소를 가져옴
node_list[del_node].is_delete = False # 해당 노드의 is_delete = False로 변경
prev_node = node_list[del_node].prev # 삭제된 노드의 이전 노드
next_node = node_list[del_node].next # 삭제된 노드의 다음 노드
if prev_node != -1: # 이전 노드가 존재하는 경우
node_list[prev_node].next = del_node # 이전 노드의 next를 현재 노드로 지정
if next_node != -1:
node_list[next_node].prev = del_node # 다음 노드의 prev를 현재 노드로 지정
|
cs |
명령어가 D인 경우 가장 최근에 삭제된 노드를 복구합니다.
우선 스택에서 가장 상위 요소를 가져옵니다. 그리고 해당 노드의 삭제 표시를 갱신합니다.
그리고 이전 노드의 next를 현재 노드로, 다음 노드의 prev를 현재 노드로 지정합니다. 그림으로 나타내면 다음과 같습니다.

이 때 현재 가리키고 있는 cur은 변화가 없습니다.
4. 삭제된 노드 판별
|
1
2
3
4
5
6
7
8
9
10
|
def solution(n, k, cmd):
...
# 4. 삭제된 노드 판별
answer = []
for i in range(n):
if node_list[i].is_delete: answer.append("X")
else: answer.append("O")
return "".join(answer)
|
cs |
명령어를 모두 처리한 후 노드리스트를 하나씩 참조하여 is_delete가 True인 경우 "X"를 아닌 경우 "O"를 answer 배열에 추가한 후 마지막에 join()함수로 문자열로 합성하여 반환합니다.
answer를 문자열로 선언하여 "X", "O"를 추가하는 방법도 있지만, 속도면에서 배열의 join()이 빠르기 때문에 이와 같이 구현하였습니다.
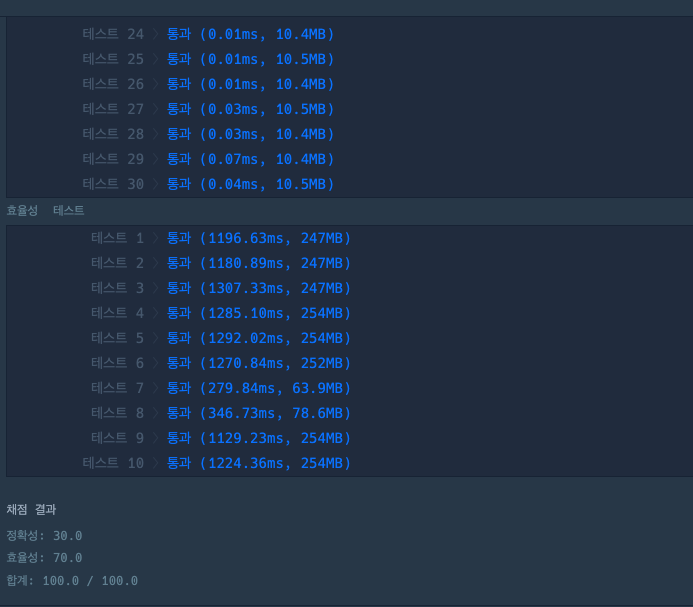
이와 같이 링크드리스트의 삭제/삽입을 구현하여 문제를 풀었습니다. 링크드리스트 특성상 삭제/삽입 시 prev노드와 next노드의 값만 변경하면 되기 때문에 원소의 삭제/삽입의 속도가 일반 배열에 비해 빠릅니다. 이러한 특성 때문에 효율성 테스트에서 통과할 수 있었습니다.
전체 소스코드
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
def solution(n, k, cmd):
# 1. 링크드리스트 초기화
node_list = [Node() for _ in range(n)] # 노드 리스트 생성
for i in range(n - 1):
node_list[i].next = i + 1 # i 번째 노드의 next는 i+1
node_list[i + 1].prev = i # i+1 번째 노드의 prev는 i
# 2. 삭제된 노드를 저장할 스택
del_stack = deque()
# 3. 명령어 처리
cur = k # 현재 가리키고 있는 노드의 인덱스
for c in cmd:
if len(c) > 1:
c, move_size = c.split(' ')
move_size = int(move_size)
if c == "U":
for i in range(move_size):
cur = node_list[cur].prev # cur을 cur 노드의 prev로 교체
elif c == "D":
for i in range(move_size):
cur = node_list[cur].next # cur을 cur 노드의 next로 교체
elif c == "C":
node_list[cur].is_delete = True # 현재 노드에 삭제 표시
del_stack.append(cur) # 스택에 삭제된 노드 번호 추가
prev_node = node_list[cur].prev # 이전 노드 번호
next_node = node_list[cur].next # 다음 노드 번호
if prev_node != -1: # 이전 노드가 있는 경우
node_list[prev_node].next = next_node # 이전 노드의 next를 삭제된 노드가 가리키던 next로 교체
if next_node != -1: # 다음 노드가 있는 경우
node_list[next_node].prev = prev_node # 다음 노드의 prev를 삭제된 노드가 가리키던 prev로 교체
cur = next_node # 가리키고 있는 노드를 next_node로 갱신
else: # 만약 다음 노드가 없는 경우
cur = prev_node # 가리키고 있는 노드를 prev_node로 갱신
elif c == "Z":
del_node = del_stack.pop() # stack의 가장 상위 요소를 가져옴
node_list[del_node].is_delete = False # 해당 노드의 is_delete = False로 변경
prev_node = node_list[del_node].prev # 삭제된 노드의 이전 노드
next_node = node_list[del_node].next # 삭제된 노드의 다음 노드
if prev_node != -1: # 이전 노드가 존재하는 경우
node_list[prev_node].next = del_node # 이전 노드의 next를 현재 노드로 지정
if next_node != -1:
node_list[next_node].prev = del_node # 다음 노드의 prev를 현재 노드로 지정
# 4. 삭제된 노드 판별
answer = []
for i in range(n):
if node_list[i].is_delete: answer.append("X")
else: answer.append("O")
return "".join(answer)
|
cs |
감사합니다.
'About > Algorithm' 카테고리의 다른 글
| [백준 23288] 주사위 굴리기 2 (Python 풀이) (0) | 2022.02.22 |
|---|---|
| [백준 23290] 마법사 상어와 복제(Python 풀이) (0) | 2022.02.14 |
| [Programmers] 파괴되지 않은 건물 (Python 풀이) - 2022 KAKAO BLIND RECRUITMENT (9) | 2022.02.03 |
| [Programmers] 양과 늑대 (Python 풀이) - 2022 KAKAO BLIND RECRUITMENT (0) | 2022.01.28 |
| [Programmers] 신고 결과 받기 (Python 풀이) - 2022 KAKAO BLIND RECRUITMENT (2) | 2022.01.24 |



